
Répondre à une question factuelle nécessite de connaître le sujet et d’être à jour sur ses évolutions. Cette limite fréquemment rencontrée par les LLMs (dont ChatGPT) peut être évitée en utilisant une nouvelle approche appelée Retrieval Augmented Generation. Dans cet article, nous expliquons en quoi consiste cette approche et comment la paramétrer pour obtenir un chatbot offrant des réponses de qualité.
Dans un article de blog précédent, nous avions présenté le phénomène des chatbots suite à l’arrivée tonitruante de ChatGPT. Un point qui avait alors retenu notre attention est le fait que ChatGPT est susceptible de donner des réponses plausibles mais fausses dans le cadre de questions factuelles. Ce phénomène est connu sous le terme « hallucination ». Ainsi, des plaisantins ont pu obtenir avec succès un discours probant (du moins pour des martiens) sur la différence entre les œufs de poules et les œufs de vaches.
Entretemps, des progrès notables sur ce point de faille ont pu être réalisés suite à une recherche intense dans ce domaine, tant par les acteurs académiques que par les acteurs du privé. Ce champ de recherche étudie dans quelle mesure les chatbots pourraient fournir des réponses correctes et actualisées dans des secteurs spécialisés, en fonction de l’évolution des connaissances dans ces domaines. Deux approches principales émergent de ces recherches :
Ces deux approches peuvent être utilisées en combinaison ou isolément.
Cet article se concentre sur la deuxième approche, appelée Retrieval Augmented Generation (RAG). Elle est réputée pour donner des réponses qualitatives tout en étant moins demandeuse en termes de ressources informatiques nécessaires pour sa mise en œuvre et sa maintenance. Nous commençons par décrire cette approche et ensuite, nous examinons 10 leviers pour améliorer son efficacité.
L’approche Retrieval Augmented Generation consiste à faciliter le travail du chatbot en lui mettant à disposition des documents relatifs à la question posée. Ainsi, au lieu de se baser sur sa connaissance générale, il utilise un ensemble de documents de référence sur lequel il se base pour formuler sa réponse. Grâce à cette architecture, et ce pour autant que la base de connaissance (soit l’ensemble des documents) soit à jour et complète, le risque d’hallucination du chatbot est fortement réduit. De plus, on peut aussi récupérer le ou les liens vers la source documentaire et réduire le risque de variation dans la réponse apportée.

De façon pratique, le RAG est un processus comprenant trois grandes étapes ;
Ces étapes sont illustrées dans le schéma ci-dessous avec un exemple issu du domaine pharmaceutique.
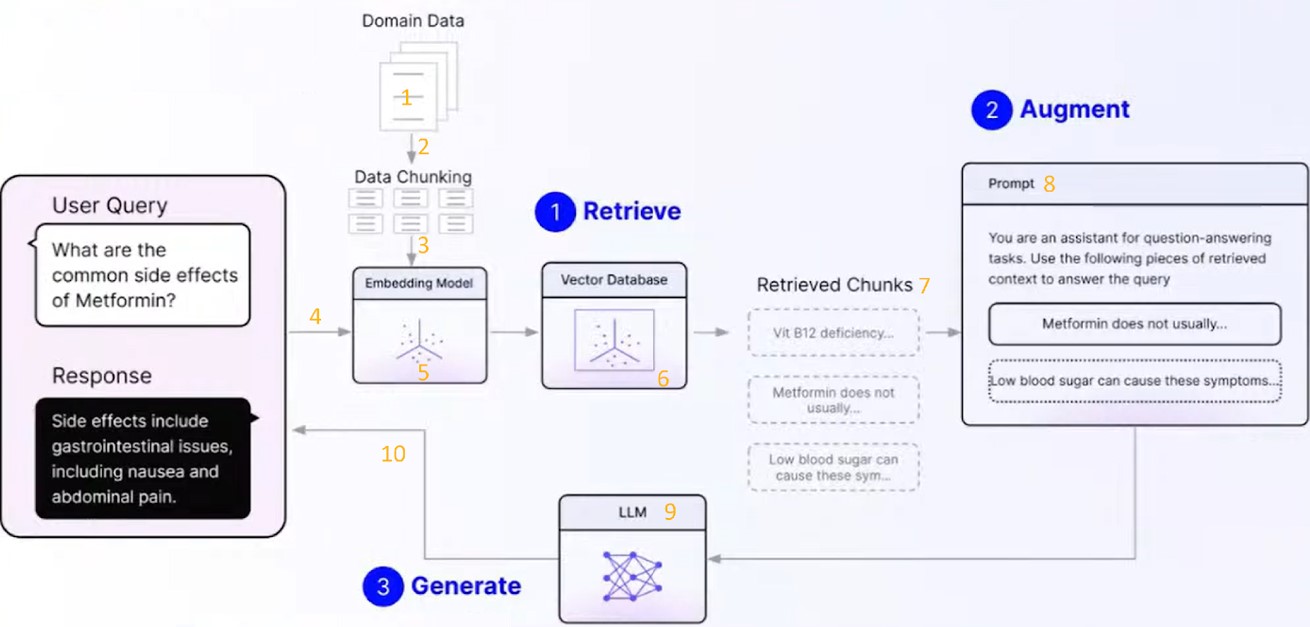
Nous avons identifié 10 leviers qui nous semblent être des points d’attention importants dans ce processus pour affiner le RAG à votre cas d’usage. Le paramétrage de ces leviers est lié à trois facteurs :
Ces 10 leviers sont identifiés dans le schéma ci-dessus. Nous les explicitons ci-après.
1. Choix des documents et de leur format
La question du choix des documents peut paraître banale mais, de retour d’expérience, il s’agit souvent du levier le plus efficace pour améliorer le RAG. Ainsi, il faut pouvoir s’assurer que l’ensemble des documents sélectionnés :
A côté du choix des documents, il y a aussi la question du choix du format des documents : si les documents sont accessibles sous un format avec balise (tel que html ou markdown), cela permet de réaliser plus facilement le deuxième levier décrit ci-dessous.
2. Découpe des documents en fragments : méthode, taille et entrecroisement
Selon la taille des documents sélectionnés lors du levier 1, il y a habituellement lieu de découper ces documents en fragments appelés “chunks”. Cette nécessité est due au fait que le LLM ne peut pas traiter un nombre d’informations (appelés “tokens”, soit habituellement les mots ou parties de mots) au-delà d’un certain nombre (il s’agit d’un seuil appelé “context window”). Cette limite est particulièrement déterminante dans le cadre d’un RAG, puisque les fragments de document sélectionnés lors de l’étape “Retrieve” sont ajoutés à la question posée par l’utilisateur comme information supplémentaire.
A minima, la taille des fragments doit donc être définie de sorte à ne pas dépasser ce seuil d’information admissible. Cependant, une approche plus élaborée consiste à tenir compte également de son impact possible sur la qualité de la réponse : selon le cas d’usage un choix de fragment trop petit peut empêcher le LLM d’avoir accès à l’ensemble de l’information utile pour répondre à la question, un choix de fragment trop grand peut diluer l’importance de l’information utile dans un fragment et donc empêcher l’étape “Retrieve” de récupérer ce fragment pourtant utile.
Les techniques de découpe en fragment sont discutées en détail dans « The 5 Levels Of Text Splitting For Retrieval ». Voici les 5 types de techniques envisagées par l’auteur selon leur niveau de sophistication :
A côté de la taille du fragment, il y a également lieu de choisir la taille de l’entrecroisement. L’entrecroisement consiste à ajouter au début d’un fragment la fin du fragment précédent. Ce procédé permet de réduire le risque qu’un ensemble de mots représentant une unité de sens ne soit dissocié entre deux fragments.
3. Choix de la représentation des fragments
Comme discuté précédemment, les fragments sont traduits en signatures digitales c’est-à-dire en vecteurs de nombre. Cependant, la question demeure : qu’allons-nous numériser ? Le choix usuel consiste à numériser le texte brut. Des approches plus avancées proposent de numériser, à la place ou en complément, un résumé et/ou des mots clés liés à ce fragment. Pour disposer de ces informations supplémentaires, un LLM peut aussi être utilisé pour les générer.
4. Choix de la représentation de la question de l’utilisateur
Le même questionnement se pose par rapport à la représentation de la question de l’utilisateur : on peut numériser la question brute de l’utilisateur ou la retravailler. Ce re-travail peut corriger d’éventuelles erreurs de langage, inclure l’ajout de nouvelles représentations telles que des synonymes de la question, ou encore découper la question de départ en une série de questions plus générales.
5.Choix du modèle réalisant la signature digitale
La transformation des deux représentations décrites ci-dessus en signature digitale nécessite le choix d’un modèle. Celui-ci peut être en accès libre (exemple : all-MiniLM-L6-v2 de Hugging Face) ou payant (exemple : text-embedding-3-small de OpenAI). Le choix d’un modèle va dépendre du prix d’accès, du prix de stockage (voir levier 6) et de la qualité de la signature. Pour la qualité de la signature, on peut s’attendre à ce que celle-ci soit meilleure pour un cas d’usage donné si le corpus qui a permis d’entraîner ce modèle couvre le domaine d’intérêt cible de façon substantielle. Le prix d’accès dans le cadre d’un modèle payant est généralement lié au nombre de mots (tokens) transmis au modèle. Le prix de stockage, dans le cadre d’une base de données payante, sera influencé par la taille de la signature (dimension du vecteur) et par sa précision numérique.
6. Choix de la base de données de stockage de la signature et de l’algorithme de récupération des fragments
Les signatures associées aux fragments sont stockées dans une base de données qui peut être en accès libre avec un stockage local (exemple : Chroma) ou payante avec un stockage, habituellement, sur un cloud (exemple : Pinecone). A ce choix de base de données, on associe également l’algorithme ou les algorithmes qui permettront d’identifier les fragments les plus proches sémantiquement de la question posée par l’utilisateur. Dans ce champ de recherche, on notera notamment une distinction entre les algorithmes qui parcourent l’ensemble des signatures des fragments pour faire cette recherche (résultat optimal obtenu mais coûteux en temps) des approches cherchant de bonnes correspondances sémantiques (sans garantie d’optimalité mais moins coûteuses en temps). Enfin, il convient également de mentionner les recherches sur des algorithmes conçus pour récupérer un ensemble de fragments avec des contenus variés, offrant une diversité sémantique parmi les fragments récupérés.
Le choix de la DB et de l’algorithme de récupération dépendent des trois facteurs discutés précédemment (la qualité voulue de la réponse, le temps de réponse et le budget. Nous suggérons, pour cette partie ainsi que pour les autres leviers, de tester d’abord une approche en accès libre pour vérifier si elle fournit des résultats satisfaisants en termes de qualité et de rapidité de réponse. Si ce n’est pas le cas, envisagez alors une solution en accès payant. Il est important de noter, spécifiquement pour ce levier, que choisir une base de données payante implique de prendre en considération les divers coûts associés à son utilisation. En particulier, les frais de stockage éventuels des données seront à payer durant toute la durée de vie du RAG quel que soit le niveau d’utilisation de celui-ci.
7. Choix du nombre de fragments extraits de la base de données
Le dernier levier lié à l’étape “Retrieve” consiste à définir le nombre de fragments que l’on va récupérer. Ce choix est à réaliser en interaction avec tous les éléments de l’architecture du RAG en lien avec le seuil d’information admissible par le LLM (discuté lors du levier 2) : la longueur admise des questions d’un utilisateur, la taille des fragments (voir levier 2), les instructions données au LLM (voir levier 8, ci-après) et le choix du LLM (voir levier 9). Plus il y a des fragments donnés au LLM, plus il y a de chances que la ou les parties utiles pour répondre à la question se retrouvent dans les fragments récupérés. Cependant, il y a également plus de chance dans ce cas que de l’information inutile ou redondante se retrouve dans ces fragments. On notera que si l’étape “Retrieve” est efficace (et donc qu’elle récupère systématiquement les fragments utiles), on aura tendance à diminuer ce nombre, tandis que si cette première étape est moins performante on aura plutôt tendance à donner un maximum de fragments et donc laisser plus de liberté au LLM à faire le tri.
8. Choix des instructions données au LLM
Une fois que les fragments utiles ont été récupérés, la deuxième étape, “Augment”, consiste à donner des instructions au LLM. Le contenu de ces instructions peut varier suivant le niveau de précision voulu par le concepteur. Au vu des retours d’expérience, il est assez communément admis que plus les instructions données au LLM sont précises au mieux les réponses sont de qualité. L’article de Santu et al. [1] discute de 5 niveaux d’instruction. Dans le cadre du RAG, on notera les informations suivantes que l’on peut mentionner dans ces instructions pour les rendre les plus complètes possibles :
9. Choix du LLM
Le choix du LLM dépend lui aussi des 3 facteurs précédemment discutés (qualité, temps de réponse et budget). Ce choix n’est cependant pas évident à mettre en œuvre de façon objective étant donné que le marché » des LLMs est un marché fort dynamique, avec une compétition soutenue entre les différents acteurs, que ce soit en accès ouvert ou payant. Concernant la qualité, il semblerait que la tendance irait vers des LLMs ayant des niveaux comparables (jusqu’à récemment dominé par ChatGPT4).
Par contre, le temps de réponse n’est pas uniquement déterminé par le modèle lui-même, mais il dépend également de l’infrastructure sur laquelle ce LLM est hébergé, ce qui soulève également des considérations budgétaires. Par exemple, faire tourner un LLM sur un laptop ou desktop standard est compliqué dans le cadre d’un RAG car le temps de réponse dépend également de la longueur du texte en entrée du LLM, cette longueur étant fortement impactée par les fragments transmis. Pour un test ou l’usage d’un RAG s’adressant à un nombre modéré d’utilisateur, le choix d’un LLM payant peut s’avérer utile pour obtenir une réponse dans un délai satisfaisant sans devoir s’équiper d’une infrastructure potentiellement coûteuse (incluant potentiellement un GPU). Une autre option est d’exploiter un hébergement cloud avec un LLM en accès libre, mais il faut s’assurer du temps de réponse dans ce cas.
10. Choix de la méthode d’évaluation et des mesures
Pour pouvoir améliorer le RAG lors de son implémentation et lors de son fonctionnement, il est nécessaire de déterminer la manière dont la qualité des réponses sera jugée. L’approche la plus habituelle mais aussi la plus chronophage consiste à faire analyser des résultats d’utilisation du chatbot par un ou plusieurs experts du domaine en question.
Cette étape peut être précédée par une première évaluation assistée par l’IA via les 3 étapes suivantes :
A côté de cette évaluation globale de la qualité de la réponse apportée par le chatbot, on peut aussi évaluer de façon séparée la partie “Retrieve” de la partie “Generate”. Dans le premier cas, on s’intéressera notamment à la proportion des cas où les fragments utiles pour apporter une réponse sont récupérés au terme de cette étape ”Retrieve”. Dans le deuxième cas, on s’intéressera à la proportion des cas où une réponse satisfaisante est apportée lorsque les bons fragments sont transmis au LLM.
Conclusion
Dans cet article, nous vous avons tout d’abord présenté une méthode appelée “Retrieval Augmented Generation” permettant de rendre un chatbot plus efficace pour répondre à des questions factuelles d’un domaine d’intérêt. L’essence de cette méthode consiste à transmettre au chatbot les références utiles liées à la question, ces références étant stockées dans une base de connaissance externe liée au domaine d’intérêt. Ensuite, nous avons discuté de 10 leviers ajustables à votre cas d’usage pour que la solution obtenue rencontre vos attentes en termes de qualité de la réponse, du temps de réponse et du budget alloué. Au CETIC, dans ce domaine de recherche, nous investiguons actuellement la possibilité de déployer automatiquement une architecture RAG incluant des choix optimaux pour ces leviers selon le cas d’usage donné.
Christian Colot, Chercheur Senior CETIC
Laurie Ceccotti, Chercheuse CETIC
[1] SANTU, Shubhra Kanti Karmaker et FENG, Dongji. Teler : A general taxonomy of llm prompts for benchmarking complex tasks. arXiv preprint arXiv:2305.11430, 2023.