
Answering a factual question requires knowledge of the subject and staying up-to-date with its developments. This limitation, often encountered by LLMs (including ChatGPT), can be avoided by using a new approach called Retrieval Augmented Generation. In this article, we explain the core principles of this approach and how to configure it to create a chatbot that provides quality responses.
In a previous blog post, we introduced the phenomenon of chatbots following the grand entrance of ChatGPT. One point that caught our attention then was that ChatGPT is likely to give plausible but false responses to factual questions. This phenomenon is known as "hallucination." Thus, pranksters have successfully obtained a convincing speech (at least for Martians) about the difference between chicken eggs and cow eggs.
In the meantime, significant progress on this issue has been made following intense research in this field, both by academic and private players. This research field studies to what extent chatbots could provide correct and up-to-date responses in specialized sectors, depending on the evolution of knowledge in these domains. Two main approaches emerge from this research:
These two approaches can be used in combination or individually. This article focuses on the second approach, known as Retrieval Augmented Generation (RAG). It is renowned for providing qualitative responses while requiring fewer computing resources for implementation and maintenance. We start by describing this approach and then examine 10 levers to enhance its effectiveness.
The Retrieval Augmented Generation approach involves facilitating the chatbot’s work by providing it with documents related to the question asked. Instead of relying on its general knowledge, it uses a set of reference documents on which it bases its response. Thanks to this architecture, and as long as the knowledge base (i.e., the set of documents) is up-to-date and complete, the risk of the chatbot’s hallucination is greatly reduced. Additionally, one can also retrieve the link(s) to the documentary source and reduce the risk of variation in the response provided.

Practically, RAG is a process comprising three major steps:
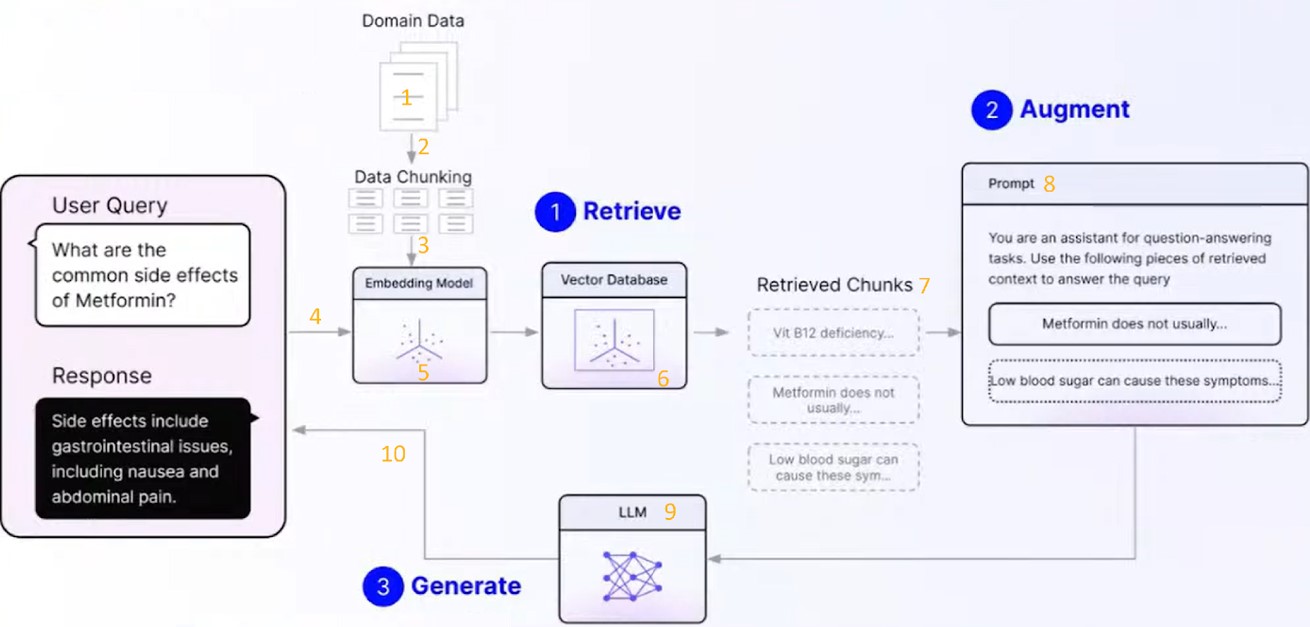
We have identified 10 levers that we believe are important points of attention in this process to refine the RAG to your use case. The setting of these levers is linked to three factors:
1. Choice of documents and their format
The issue of document selection may seem trivial, but from experience, it is often the most effective lever for improving RAG. It is essential to ensure that the set of selected documents:
Besides the choice of documents, there is also the issue of the format of the documents: if the documents are available in a tagged format (such as HTML or markdown), this allows easier execution of the second lever described below.
2. Segmenting Documents into Fragments: Method, Size, and Overlapping
Depending on the size of the documents selected in lever 1, it is usually necessary to segment these documents into fragments called "chunks." This need arises because the LLM cannot process a number of information units (called "tokens," usually words or parts of words) beyond a certain threshold (known as "context window"). This limit is particularly decisive in the context of RAG, as the document fragments selected during the "Retrieve" step are added to the question posed by the user as additional information. At a minimum, the size of the fragments must be defined so as not to exceed this permissible information threshold. However, a more sophisticated approach also considers its possible impact on the quality of the response: depending on the use case, choosing a fragment too small may prevent the LLM from accessing all the useful information to answer the question, while choosing a fragment too large may dilute the importance of the useful information in a fragment and thus prevent the "Retrieve" step from recovering this fragment.
Fragment cutting techniques are discussed in detail in "The 5 Levels Of Text Splitting For Retrieval". Here are the 5 types of techniques considered by the author according to their level of sophistication:
3. Choice of Fragment Representation
As previously discussed, fragments are translated into digital signatures, that is, numerical vectors. However, the question remains: what are we going to digitize? The usual choice is to digitize the raw text. More advanced approaches propose to digitize, in addition or alternatively, a summary and/or keywords related to the fragment. To have this additional information, an LLM can also be used to generate it.
4. Choice of the User’s Question Representation
The same questioning applies to the representation of the user’s question: one can digitize the user’s raw question or rework it. This reworking can correct potential language errors, include the addition of new representations such as synonyms of the question, or further divide the initial question into a series of more general questions.
5. Choice of Model for Digital Signature
Transforming the two representations described above into a digital signature requires choosing a model. This model can be open access (example: all-MiniLM-L6-v2 from Hugging Face) or paid (example: text-embedding-3-small from OpenAI). The choice of a model will depend on the access price, storage cost (see lever 6), and the quality of the signature. Regarding the quality of the signature, one can expect it to be better for a given use case if the corpus that trained this model substantially covers the target interest domain. The access price in the case of a paid model is generally linked to the number of words (tokens) transmitted to the model. The storage price, in the case of a paid database, will be influenced by the size of the signature (vector dimension) and its numerical precision.
6. Choice of Database for Signature Storage and Fragment Retrieval Algorithm
The signatures associated with the fragments are stored in a database that can be in open access with local storage (example: Chroma) or paid with storage usually on a cloud (example: Pinecone). To this database choice, we also need to consider the algorithms that are available to identify the fragments semantically closest to the question posed by the user. In this research field, we particularly note a distinction between algorithms that browse all the fragment signatures to conduct this search (optimal result obtained but time-consuming) and approaches seeking good semantic matches (without guarantee of optimality but less time-consuming).
Finally, it is also worth mentioning research on algorithms designed to retrieve a set of fragments with varied contents, offering semantic diversity among the retrieved fragments. The choice of the DB and the retrieval algorithm depends on the three factors discussed previously (the desired quality of the response, the response time, and the budget. For this part, as well as for the other levers, we suggest first testing an open access approach to verify if it provides satisfactory results in terms of quality and speed of response. If not, then consider a paid access solution. It is important to note, specifically for this lever, that choosing a paid database involves considering the various costs associated with its use. In particular, any data storage fees will be paid throughout the life of the RAG regardless of its level of use.
7. Choice of the Number of Fragments Extracted from the Database
The last lever related to the "Retrieve" step involves defining the number of fragments to be recovered. This choice is made in interaction with all the elements of the RAG architecture linked to the permissible information threshold by the LLM (discussed during lever 2): the permissible length of a user’s questions, the size of the fragments (see lever 2), the instructions given to the LLM (see lever 8, below) and the choice of the LLM (see lever 9). The more fragments given to the LLM, the more likely it is that the useful parts for answering the question will be found in the recovered fragments. However, there is also a greater chance in this case that unnecessary or redundant information will be found in these fragments. It should be noted that if the "Retrieve" step is effective (and thus systematically recovers useful fragments), we tend to decrease this number, while if this first step is less efficient we tend to give the maximum number of fragments and thus leave more freedom for the LLM to sort them out.
8. Choice of Instructions Given to the LLM
Once the useful fragments have been recovered, the second step, "Augment," consists of giving instructions to the LLM. The content of these instructions may vary depending on the level of precision desired by the designer. Based on experience feedback, it is commonly accepted that the more precise the instructions given to the large language model are, the higher the quality of its responses. The article by Santu et al. [1] discusses 5 levels of instruction. In the context of RAG, the following information can be noted in these instructions to make them as complete as possible:
9. Choice of LLM
The choice of LLM also depends on the three factors previously discussed (quality, response time, and budget). However, this choice is not easy to implement objectively given that the LLM market is a very dynamic market, with strong competition between various actors, whether open access or paid. Regarding quality, the trend seems to be towards LLMs with comparable levels (until recently dominated by ChatGPT4).
However, the response time is not solely determined by the model itself, but also depends on the infrastructure on which this LLM is hosted, which also raises budgetary considerations. For example, running an LLM on a standard laptop or desktop is complicated in the context of a RAG because the response time also depends on the length of the text input to the LLM, this length being significantly affected by the transmitted fragments. For a test or the use of a RAG addressing a moderate number of users, the choice of a paid LLM may be useful to obtain a response within a satisfactory timeframe without having to equip oneself with potentially costly infrastructure (potentially including a GPU). Another option is to use cloud hosting with an open access LLM, but one must ensure the response time in this case.
10. Choice of Evaluation Method and Measures
To improve the RAG during its implementation and operation, it is necessary to determine how the quality of the responses will be judged. The most common but also most time-consuming approach involves having the results of the chatbot’s use analyzed by one or more experts in the relevant field.
This step may be preceded by an initial evaluation assisted by AI through the following three steps:
Besides this global evaluation of the quality of the response provided by the chatbot, the "Retrieve" part can also be evaluated separately from the "Generate" part. In the first case, we will particularly focus on the proportion of cases where the useful fragments to provide a response are recovered at the end of this "Retrieve" step. In the second case, we will focus on the proportion of cases where a satisfactory response is provided when the correct fragments are transmitted to the LLM.
Conclusion
In this article, we first introduced a method called "Retrieval Augmented Generation" that makes a chatbot more effective in answering factual questions from an interest domain. The essence of this method involves transmitting to the chatbot the useful references related to the question, these references being stored in an external knowledge base linked to the interest domain. Then, we discussed 10 adjustable levers for your use case so that the solution obtained meets your expectations in terms of the quality of the response, the response time, and the allocated budget. At CETIC, in this research area, we are currently investigating the possibility of automatically deploying a RAG architecture including optimal choices for these levers according to the given use case.
Christian Colot, Senior R&D Engineer CETIC
Laurie Ceccotti, Researcher CETIC
[1] SANTU, Shubhra Kanti Karmaker et FENG, Dongji. Teler: A general taxonomy of llm prompts for benchmarking complex tasks. arXiv preprint arXiv:2305.11430, 2023.