
Cet article présente le projet CANAPE dont l’objectif est d’étudier et de développer un prototype d’accélérateur matériel à base de FPGA permettant d’accélérer l’exécution des opérations de la librairie BLAS.
Fiche projet:
En septembre 2005, le CETIC a entamé un travail de recherche collective dans le domaine de la microélectronique. Celui-ci s’intitule : CANAPE (CAlcul Numérique sur Architecture ProgrammablE). Sont associés au projet des partenaires industriels tels que Open Engineering et Thales Alenia Space Etca, acteurs majeurs respectivement dans les domaines de la simulation numérique et de la microélectronique.
Les objectifs de cette recherche sont d’étudier et de développer un prototype d’accélérateur matériel à base de FPGA visant à décentraliser et à accélérer l’exécution des opérations algébriques de la librairie BLAS (voir section suivante). En effet, de nombreux logiciels, tels que les logiciels de simulation numérique ou de prototypage virtuel, passent plus de 90% de leur temps de calcul dans des opérations de la librairie BLAS. L’exécution de ces opérations par la carte accélératrice au lieu du processeur central de l’ordinateur hôte permettrait de globalement accélérer les calculs. Cette décentralisation des calculs est implémentée de manière à être transparente pour l’utilisateur.
Actuellement, un processeur de type Intel P4 Dual Core 3 GHz affiche des performances maximales de l’ordre de 3,3 Gflops/s pour la multiplication matricielle de matrices 1000x1000. Ce résultat est obtenu en mettant en oeuvre les algorithmes optimisés de la librairie Atlas (« Automatically Tuned Linear Algebra Software »). Le prototype développé présente des performances sensiblement supérieures avec un résultat mesuré expérimentalement de 5,08 Gflops/s.

Le besoin de réaliser ce travail de recherche a pour origine une augmentation significative, depuis plusieurs années, de la qualité et de la précision des modèles produits par les logiciels de prototypage virtuel et de simulation numérique. Cette qualité et cette précision vont de pair avec un important besoin en puissance de traitement, ce qui se traduit bien souvent par des temps de calculs élevés. La solution actuelle pour tenter de diminuer ces temps de calcul importants consiste à multiplier le nombre de processeurs au sein d’une même machine. Cette solution est cependant sous-optimale et très onéreuse.
A côté des processeurs classiques, un autre type de composant matériel se distingue pour ce genre d’application : ce sont les composants à logique programmable. Ils consistent en une matrice de plusieurs millions d’éléments logiques connectés ensemble afin de réaliser une fonctionnalité donnée. Ils peuvent être aisément reprogrammés par l’utilisateur. Un de leurs intérêts par rapport aux processeurs classiques est de pouvoir réaliser un grand nombre d’opérations en parallèle. Plusieurs constructeurs de superordinateurs tels que Cray (http://www.cray.com/products/xd1/acceleration.html) s’intéressent à l’utilisation des performances des FPGA pour accélérer les traitements logiciels.
Les opérations algébriques telles que la multiplication matricielle ou la factorisation sont d’une grande importance dans de nombreux algorithmes logiciels de résolution de système. Pour cette raison, elles sont bien souvent regroupées en librairies standardisées. Une des plus répandue est la librairie BLAS (Basic Linear Algebraic Subprogram). Cette librairie définit une interface standard et une implémentation de base pour une série d’opérations algébriques. Elles sont rassemblées en 3 niveaux suivant le type des opérandes :
![]() Niveau 1 : les opérandes sont de type vecteur-vecteur
Niveau 1 : les opérandes sont de type vecteur-vecteur
![]() Niveau 2 : les opérandes sont de type vecteur-matrice
Niveau 2 : les opérandes sont de type vecteur-matrice
![]() Niveau 3 : les opérandes sont de type matrice-matrice
Niveau 3 : les opérandes sont de type matrice-matrice
La première partie du travail a d’une part consisté à étudier la librairie BLAS et à sélectionner un panel d’opérations à implémenter et, d’autre part, a permis de calculer théoriquement le gain de performances attendu d’un tel système et à déterminer les contraintes matérielles et logicielles.
Grâce à leur expérience en matière de logiciels de simulation numérique, Open Engineering a désigné la multiplication matricielle comme une des opérations matricielles BLAS intéressante à implémenter vu que celle-ci tient une place importante dans de nombreux algorithmes de résolution de système. Accélérer cette opération permettrait d’accélérer globalement la résolution d’un système.
L’étude réalisée a permis de mettre en avant l’influence que les transferts de données ont sur les performances globales du système. Les transferts de données considérés sont effectués d’une part entre la mémoire centrale du PC hôte et la mémoire de la carte FPGA et d’autre part entre cette même mémoire et le FPGA lui-même (voir figure 2).
Les performances des transferts entre le PC hôte et la carte sont directement liées au type d’interface de la carte FPGA. Actuellement l’interface la plus rapide qui équipe une carte FPGA est le PCI Express 8x qui offre une bande passante maximale de 4 Gbytes/s.
Les performances de transferts entre la RAM de la carte FPGA et le FPGA dépendent du type de mémoire RAM et des performances du contrôleur mémoire bien souvent présent sous forme de bloc à synthétiser dans le FPGA. Les mémoires couramment utilisées sur les cartes FPGA sont de type DDRII SDRAM offrant une bande passante maximale, à 200 Mhz, de l’ordre de 1,6 Gbytes/s pour un bus de données de 64 bits et 0,8 Gbytes/s pour un bus de données de 32 bits.
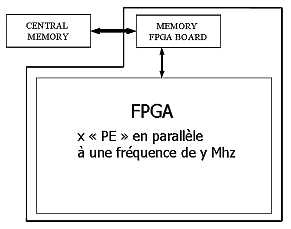
Un modèle fonctionnel de multiplieur matriciel réalisé au cours de cette première partie du projet a permis de justifier l’intérêt de la recherche entreprise. Ce modèle met en œuvre une architecture optimisée de multiplieur matriciel. Il est composé de plusieurs unités de calcul, appelées les « Processing Elements (PE) », organisées en « pipeline » et fonctionnant en parallèle. Cette structure permet de considérablement diminuer le besoin en bande passante entre la RAM de la carte FPGA et le FPGA.
Ce modèle affiche des performances de calcul bien supérieures aux processeurs classiques. Elles dépendent principalement de deux facteurs : La densité du ou des FPGA qui composent le prototype et la fréquence maximale de fonctionnement. Pour une carte FPGA composée de 2 FPGA Altera StratixII 60 fonctionnant à 200 Mhz et pouvant contenir chacun 16 PE fonctionnant en parallèle, les performances théoriques de calcul atteignent 12,8Gflops/s.
Ces résultats sont obtenus en considérant que les transferts de données ont un rendement maximal. En réalité, une RAM DDRII cadencée à 200 Mhz fournira des données valides à une fréquence moyenne de 160 Mhz.
A côté des performances de calcul, il faut également considérer les temps de transferts de données entre la RAM centrale du PC hôte et la RAM de la carte FPGA. Etant donné que les RAM actuelles de grosse capacité ne sont pas accessibles simultanément en écriture et en lecture, ces temps de transferts se rajoutent aux temps de calcul à proprement parler ce qui diminue les performances globales du système.
En tenant compte de ces constatations, les performances globales d’une carte constituée de 2 FPGA StratixII 60 fonctionnant à 160 Mhz et d’un interface PCI Express 8x sont de : 9,64 Gflops/s.
Un processeur Intel P4 3 Ghz dual core offre des performances de calcul de 3,3 Gflops/s.
La seconde partie du projet a consisté à réaliser un prototype fonctionnel basé sur une carte FPGA générique. La carte sélectionnée est une carte bi-FPGA de Gidel : la ProcStarII (voir figure 3). Elle est composée de deux FPGA Altera StratixII 60 et de 256 Mbytes de DDRII SDRAM « onboard ». Outre cette mémoire « onboard », le deuxième FPGA est connecté à une interface SODIMM permettant de rajouter jusqu’à 1 Gbyte de DDRII SDRAM. La carte dispose d’une interface de type PCI 64 bits 66 Mhz offrant une bande passante maximale de 500 Mbytes/s.

La complexité du design et l’encombrement du FPGA ne permettent pas de placer plus de 14 PE dans chaque FPGA.
Grâce à une gestion optimisée de la RAM disponible sur la carte FPGA, chaque FPGA peut recevoir 2 mots de 64 bits à une fréquence maximale mesurée de 140 Mhz. Ce qui représente une bande passante totale de 4,48 Gbytes/s.
Outre le développement FPGA, un effort particulier a été consacré au développement de la partie logicielle du projet. La fonction de multiplication matricielle de la librairie BLAS a été ré-implémentée afin de tirer parti de la puissance de calcul de l’accélérateur FPGA. Cette implémentation est optimisée de manière à maximiser les performances en entremêlant au maximum les phases de transferts de données et de calcul. Cela permet de minimiser les phases pendant lesquelles soit le processeur, soit les FPGA ne travaillent pas.
Les performances obtenues ont été mesurées pendant l’exécution réelle de la multiplication matricielle. Elles élèvent à 5,08 Gflops/s. Cette différence de performances par rapport aux 9,64 Gflops/s annoncés par la théorie s’explique par différents facteurs :
![]() La fréquence est de 140 Mhz au lieu de 160 Mhz
La fréquence est de 140 Mhz au lieu de 160 Mhz
![]() Les FPGA intègrent 14 PE au lieu de 16
Les FPGA intègrent 14 PE au lieu de 16
![]() L’interface de la carte est de type PCI 64 bits 66 Mhz au lieu de PCI - Express 8x ce qui divise par 8 les performances maximales de transfert
L’interface de la carte est de type PCI 64 bits 66 Mhz au lieu de PCI - Express 8x ce qui divise par 8 les performances maximales de transfert
![]() De nombreuses opérations logicielles de conversion de données diminuent globalement les performances.
De nombreuses opérations logicielles de conversion de données diminuent globalement les performances.
Ce projet a permis de mettre en évidence le potentiel des FPGA pour le calcul haute performance. Le prototype développé affiche des performances sensiblement supérieures à celles d’un processeur haut de gamme.
Actuellement le facteur limitant principal se situe au niveau des transferts de données qui n’offrent pas un niveau de performances suffisant que pour permettre aux FPGA de travailler à plein régime.
Le prototype réalisé dans cette étude met en œuvre l’opération de multiplication matricielle. Il serait intéressant par la suite d’étudier et d’intégrer un plus grand nombre d’opérations telles que la factorisation LU, et autres opérations matricielles.
Publications



