
This paper presents the results of the CANAPE project. The main objectives of this project are to study and to develop a prototype of FPGA based Hardware accelerator.
Factsheet:
In September 2005, the CETIC has initiated a Collective Research Project in the field of microelectronics. This project is entitled: CANAPE (CAlcul Numérique sur Architecture ProgrammablE). Industrial partners such as Open Engineering and Thales Alenia Space Etca are associated to this project. They are major actors respectively in the fields of the numerical simulation and microelectronics.
Over the last few years, the quality and the precision of the models produced by virtual prototyping and numerical simulation softwares increased significantly. But keeping up with such high standards of quality and precision requires the increase of the computation power. The existing solution so far consists in decreasing the long times of calculation by multiplying the number of processors within the same computer. This solution is however sub-optimal and very expensive.
Next to the classic processors, another type of hardware component distinguishes itself for this kind of application: programmable logic components. They consist in a matrix of several million logical elements connected together to realize a given feature. They can be easily reprogrammed by the user. One of their advantages compared to the classic processors is to realize a big number of operations in parallel. Several supercomputers manufacturers such as Cray for example (http://www.cray.com/products/xd1/acceleration.html) are interested in the use of the performances of the FPGA to accelerate softwares.
The objectives of this research are to study and to develop a prototype of FPGA based Hardware accelerator. The purpose of this Hardware accelerator is to decentralise and to speed up the execution of the algebraic operations of the BLAS library (see following section). Indeed, many software applications, such as the software for numerical simulation or virtual prototyping, use more than 90 % of their calculation time in BLAS routines. The idea is to delegate the execution of these operations to the FPGA board; and as it can perform them much more efficiently than a general-purpose processor, the global performance of the system is improved. This mechanism obviously has to be completely transparent for the user.
Currently, the maximal performances of a processor Intel P4 Dual Core 3 GHz are 3,3 Gflops/s for the operation of matrix multiplication (matrices 1000x1000). This result is obtained by implementing the optimized algorithms of the ATLAS library (« Automatically Tuned Linear Algebraic Software ») (http://www.netlib.org/atlas/). For the same operation, the developed prototype is 54% faster with a measured performance of 5,08 Gflops/s.

The algebraic operations such as the matrix multiplication or the factorisation are a key factor of numerous software algorithms of systems resolution. For this reason, these operations are often grouped together in standardised libraries. One of the most used library is the BLAS one (Basic Linear Algebraic Subprogram). This library defines a standard interface and a standard implementation for basic vector and matrix operations. They are grouped in 3 levels following the type of the operands:
![]() Level 1: Operands of type vector-vector
Level 1: Operands of type vector-vector
![]() Level 2: Operands of type vector-matrix
Level 2: Operands of type vector-matrix
![]() Level 3: Operands of type matrix-matrix
Level 3: Operands of type matrix-matrix
These operations can be easily reimplemented by the user to optimize their performances.
Link to the BLAS libary website : http://www.netlib.org/blas
The first part of the CANAPE research project consisted in studying the BLAS library and selecting a group of BLAS operations to be implemented on the one hand. On the other hand the objective was to calculate the theorical performances expected from such a system and in determine the hardware and software constraints.
Thanks to their experience in software of numerical simulation, the Open Engineering partner indicated the matrix multiplication as one of the interesting BLAS matrix operations to implement as it has an important role in numerous system resolution algorithms. In a word, accelerating this operation would lead to accelerate globally the resolution of a system.
The theoretical study shows the influence of the data transfers on the global performances of the system. The considered transfers of data are performed between the main memory of the host PC and the memory of the FPGA board on the one hand, and on the other hand between the same memory and the FPGA itself (see figure 2).
The performances of the data transfers between the host PC and the board are directly linked to the type of interface of the FPGA board. Currently the fastest interface of a FPGA board is the PCI Express 8x which offers a maximal bandwidth of 4 Gbytes/s.
The performances of the data transfers between the RAM of the FPGA board and the FPGA depend on the type of the considered memory and on the performance of the memory controller very often present in the form of a module to be synthesised in the FPGA. The memories usually used on FPGA board are of type DDRII SDRAM which offers a maximal bandwidth of 1,6 Gbytes/s, at a frequency of 200 Mhz, for a bus of data of 64 bits and 0,8 Gbytes/s for a bus of data of 32 bits.
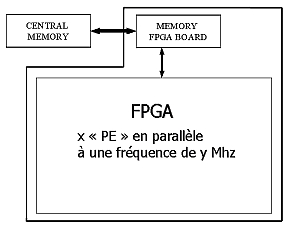
A functional model of the matrix multiplier realised during this first part of the project allowed to justify the interest of the research. This model implements an optimised architecture. It consists in several units of calculation, called the "Processing Elements (PE)", organised in "pipeline" and working in parallel. This structure decreases considerably the need in bandwidth between the RAM of the FPGA board and the FPGA itself.
This model has performances of calculation much superior to the classic processors. These performances depend mainly on two factors: the density of the FPGA which composes the prototype and the maximal running frequency. An FPGA board with 2 FPGA Altera StratixII 60 can contain a maximum of 16 PE working in parallel in each FPGA. At a frequency of 200 Mhz the theoretical performances of calculation achieve 12,8Gflops/.
These results are obtained by considering tthe data transfers as having a maximal yield. In reality, a RAM DDRII running at a frequency of 200 Mhz is able to supply valid data with an average frequency of 160 Mhz.
Next to the performance of calculation, it is also necessary to take into consideration the data transfer time between the central RAM of the host PC, and the RAM of the FPGA board. Given that current RAM of big capacity are not accessible simultaneously in writing and in reading, these transfer times are added to the times of calculation that reduces the global performance of the system.
By taking into account these observations, the global performances of a board containing 2 FPGA StratixII 60 working at a frequency of 160 Mhz and an interface PCI Express 8x are of: 9,64 Gflops/.
A Intel P4 3 Ghz dual core processor offers performances of calculation of 3,3 Gflops/.
The second part of the project consisted in realising a functional prototype based on a generic FPGA board. The selected board is a bi-FPGA board from Gidel: the ProcStarII. It contains two FPGA Altera StratixII 60 and 256 Mbytes of « onboard » DDRII SDRAM. Besides this “onboard” memory, the second FPGA is connected to an SODIMM interface allowing to add up to 1 Gbyte of DDRII SDRAM. The card possesses an interface of type PCI 64 bits 66 Mhz offering a maximal bandwidth of 500 Mbytes/.

The complexity and the density of the design do not allow to place more than 14 PE in each FPGA.
Thanks to an optimised management of the RAM available on the FPGA board, every FPGA is able receive 2 words of 64 bits with an average maximal frequency of 140 Mhz. This represents a total bandwidth of 4,48 Gbytes/.
Besides the FPGA design, a particular effort was dedicated to the development of the software part of the project. The function of matrix multiplication of the BLAS library was reimplemented to take advantage of the power of calculation of the FPGA accelerator. This implementation is optimised to maximise the performance by mixing the data transfer phases and the calculation phases. It allows to minimise the phases during which either the processor, or the FPGA does not work.
The performance obtained was measured during the real execution of the matrix multiplication. The obtained results are : 5,08 Gflops/s. The performance difference with regard to 9,64 Gflops/s announced by the theory can be explained by various factors:
![]() The frequency is 140 Mhz instead of 160 Mhz
The frequency is 140 Mhz instead of 160 Mhz
![]() The FPGA integrates 14 PE instead of 16
The FPGA integrates 14 PE instead of 16
![]() The interface of the card is of type PCI 64 bits 66 Mhz instead of PCI Express 8x what divides by 8 the maximal performances of transfer
The interface of the card is of type PCI 64 bits 66 Mhz instead of PCI Express 8x what divides by 8 the maximal performances of transfer
![]() Numerous software operations of conversion of data globally decrease the performances.
Numerous software operations of conversion of data globally decrease the performances.
This project puts in evidence the potential of the FPGA for high performance computing applications. The developed prototype shows really superior performance compared to high-end processors.
Currently, the main limiting factor for the performance is the data transfer which does not offer a sufficient level of performance to allow the FPGA to work at full speed.
The prototype developped in this study implements the matrix multiplication operation. It would be interesting afterwards to study and integrate a larger number of operations such as the factorisation LU, and other matrix operations.
Publications

