
Le projet PSOPP consiste à réaliser une méthodologie permettant d’adapter les logiciels des PME conçus pour une exécution sur processeur (CPU) mono-cœur vers une exécution sur processeurs graphiques (GPU) massivement multi-cœurs, sur CPU multi-cœurs ou sur plateforme accélératrice FPGA de manière à tirer le meilleur profit de puissance de traitement qu’offrent ces architectures.
En plus de l’amélioration des temps de traitements, l’optimisation d’applications grâce à la méthodologie développée dans le cadre du projet, va permettre aux entreprises d’optimiser leur architecture, de réduire les coûts et d’abaisser la consommation électrique. De plus la méthodologie s’applique indépendamment de l’architecture d’origine. Elle est donc susceptible d’apporter une solution à un grand nombre de sociétés en Wallonie.
Les études de cas réels réalisés dans le cadre du projet PSOPP ont montré la nécessité d’aller au-delà de la parallélisation et inclure celle-ci dans une méthodologie d’optimisation plus globale. En effet la parallélisation de traitements n’a aucun sens si elle ne s’accompagne pas d’optimisation du logiciel d’origine.
Cet article reprend la méthodologie qui décrit une procédure enchaînant chacun des processus relatifs à chaque étape de l’optimisation.
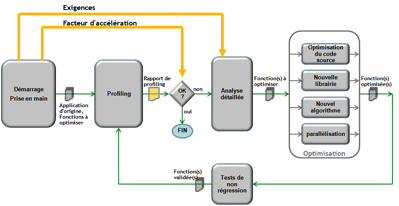
1. Tout d’abord lors d’une phase de démarrage avec l’entreprise propriétaire de l’application, les fonctions à optimiser sont identifiées ainsi que les exigences à prendre en compte telles que les ressources de parallélisation envisageables, ou le facteur d’accélération souhaitable. La réinstallation complète ou partielle de l’application sur une plateforme d’optimisation donne lieu au premier profilage, avant toute opération d’optimisation. Cela fournit une référence des performances de l’application pour évaluer par la suite le gain apporté par les optimisations.
2. L’analyse du rapport de profilage localise les parties de code les plus consommatrices de temps sur lesquelles une optimisation devrait être envisagée. La mise en œuvre de chaque optimisation doit prendre en compte les exigences formulées par l’entreprise tels que le coût de mise en œuvre ou le temps de développement. Ensuite, il s’agit d’identifier les options d’optimisation envisageables, d’en évaluer leur coût (temps de développement, options matérielles) et leur potentiel de gain de vitesse. Cette phase définie le type d’optimisation à réaliser et les fonctions qui seront impactées.
3. C’est dans la phase d’optimisation que l’application va subir des modifications pour gagner en vitesse d’exécution. Ces modifications peuvent être de différents types.
a) Des apports de corrections de bas niveau.
b) Le recours à une librairie ou un algorithme externe, sous forme de code source ou sous forme de code exécutable.
Un algorithme externe dont la précision de traitement peut être moindre que celle d’origine mais restant cependant compatible avec l’application, peut accélérer significativement l’exécution. Les librairies sont généralement des composants logiciels éprouvés qui bénéficient déjà d’optimisations internes mais il faut au préalable en évaluer les coûts d’acquisition et d’intégration, la pérennité, la robustesse et le potentiel d’accélération sur l’application.
c) La parallélisation sur des ressources matérielles supplémentaires : CPU multi-cœur, GPU ou FPGA.
Une analyse préliminaire de la nature des calculs à effectuer, des dépendances des données et des transferts de données conclue sur le choix de la technologie retenue. Ensuite le développement se décompose en plusieurs étapes :
4. Lorsque les tests de non régressions sont satisfaisants, alors une nouvelle mesure de profilage indique les performances obtenues et permet d’identifier l’objet de la prochaine optimisation.
Chaque itération de la procédure permet de gagner en vitesse d’exécution progressivement en appliquant les modifications une par une. L’optimisation est donc un processus itératif qui se justifie par le fait qu’il est difficile, voir impossible, de prédire le facteur d’accélération suite à une optimisation donnée. Il est appliqué autant de fois que nécessaire pour atteindre le meilleur facteur d’accélération possible compte tenu des contraintes (temps coût, matériel) fixées par l’entreprise propriétaire de l’application.
Comme mentionné précédemment, cette méthodologie a été établie à partir d’études de cas industriels réels issus de secteurs divers tels que la simulation de structures métalliques, la cristallographie, la bio-informatique ou encore les télécommunications. Ces études ont donné lieu à des développements sur plusieurs technologies, CPU multi-cœurs, GPU et FPGA. Cette dernière étant décrite dans l’article "Accélération d’algorithmes sur carte FPGA".
Le projet a été présenté lors du symposium "Future Generation of Processors and Systems" organisé à l’université de Mons le 09/11/2013. Ensuite le groupe de discussion "Potentiels de la technologie FPGA dans la conception des systèmes", organisé par le CETIC en décembre 2012, a donné lieu à une présentation de la méthodologie d’optimisation devant un public d’industriels.
N’hésitez pas à contacter Gérard Florence, Ingénieur de Recherche Senior au CETIC, pour plus de détails à propos de cet article.