
Face à l’accroissement de la complexité des calculs et des volumes de données à traiter, l’informatique haute performance (High Performance Computing) est aujourd’hui fondamentale pour la compétitivité des entreprises. Impliquant des investissements lourds, ce domaine semble réservé aux grandes sociétés. Cependant, il est possible d’améliorer les performances d’exécution d’un programme pour un coût maitrisé en ayant recours à une ou plusieurs cartes d’accélération connectées sur le port PCIe de la machine. La charge du processeur principal est alors répartie sur ces ressources de traitement supplémentaires. Parmi les technologies d’accélération, étudiées dans le projet de recherche PSOPP, les FPGA offrent une solution performante de parallélisation de par leurs ressources configurables.
L’architecture matérielle programmable du FPGA permet l’exécution simultanée de traitements identiques ou différents sur un volume de données important par l’instanciation de blocs fonctionnels personnalisés. Le FPGA apparaît comme un coprocesseur spécialisé, dédié à des traitements parallèles répétitifs, continus. Les performances sur des applications de calculs intensifs et parallèles (calcul vectoriels, matriciels) sont alors limitées par les ressources du circuit. L’emploi de cette technologie est tout à fait pertinent dans des applications telles que le traitement de signal, le calcul arithmétique, matriciel, statistique ou encore la cryptographie.
La parallélisation se traduit par des échanges de données entre le reste du programme exécuté sur le CPU principal et le traitement porté sur FPGA. Les transferts de données doivent être optimisés pour ne pas pénaliser le temps de traitement global qui se décompose ainsi :
![]() 1. Transfert des données de la mémoire principale vers la mémoire de la carte FPGA via le bus PCIe
1. Transfert des données de la mémoire principale vers la mémoire de la carte FPGA via le bus PCIe
![]() 2. Lecture des données en mémoire de la carte FGPA par le traitement parallélisé
2. Lecture des données en mémoire de la carte FGPA par le traitement parallélisé
![]() 3. Exécution du traitement parallélisé
3. Exécution du traitement parallélisé
![]() 4. Écriture du résultat du traitement parallélisé dans la mémoire de la carte FPGA
4. Écriture du résultat du traitement parallélisé dans la mémoire de la carte FPGA
![]() 5. Transfert des données de la mémoire de la carte FPGA vers la mémoire principale via le bus PCIe
5. Transfert des données de la mémoire de la carte FPGA vers la mémoire principale via le bus PCIe
L’accélération par FPGA nécessite donc la mise en œuvre des communications de données avec le CPU principal en plus de l’implémentation de l’algorithme dans le FPGA. Plusieurs architectures de parallélisations sur FPGA sont bien sûr envisageables. Ainsi il peut être indispensable d’avoir recours à plusieurs cartes accélératrices ou bien à des cartes munies de plusieurs FPGAs. Cependant si la mise en œuvre diffère, les étapes du développement restent les mêmes :
![]() 1. Migration du code d’origine des traitements à paralléliser en langage de programmation des FPGA (VHDL).
1. Migration du code d’origine des traitements à paralléliser en langage de programmation des FPGA (VHDL).
![]() 2. Interfaçage des traitements parallélisés avec les ressources mémoires et communication PCIe de la carte d’accélération
2. Interfaçage des traitements parallélisés avec les ressources mémoires et communication PCIe de la carte d’accélération
![]() 3. Intégration du design FPGA complet
3. Intégration du design FPGA complet
![]() 4. Insertion des appels à l’API de communication CPU/FPGA dans le programme principal exécuté sur le CPU host.
4. Insertion des appels à l’API de communication CPU/FPGA dans le programme principal exécuté sur le CPU host.
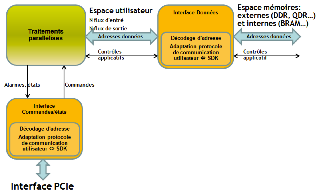
Finalement, le FPGA intègre un design qui englobe les traitements parallélisés connectés aux ressources de communication de la carte d’accélération.
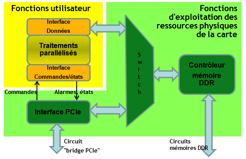
Cette architecture peut être mise en œuvre de différentes façons en fonction de l’outil utilisé et de la plateforme FPGA.
Tout d’abord, il y des outils complets qui prennent en charge tout le processus de conception FPGA. Cela inclut, comme vu précédemment, les fonctions utilisateur mais aussi celles de d’exploitation des ressources de la carte. La mise en œuvre de l’API de communication avec le CPU host fait partie aussi du processus d’accélération que permet l’outil. Ainsi CoDevelopper de Impulse Accelerated Technologies, ou Altera OpenCL génèrent automatiquement les blocs hardware (contrôleur mémoire, interface PCIe) pour une gamme de plateformes données.
Ensuite la deuxième catégorie d’outils concerne ceux qui assurent uniquement le transfert de code C, C++, System C vers le VHDL ou RTL. Ces outils sont prévus pour le portage d’algorithme en FPGA avec pour objectif de diminuer le temps de développement en évitant la conception de bas niveau propre aux développements en VHDL. Cela représente un avantage pour la plupart des développements en général. C’est le cas, par exemple, pour la réutilisation de fonctions de traitement de signal (filtrage, corrélation, FFT…) déjà développées en langage C. Il reste encore à intégrer le design complet incluant les blocs de communications et de stockages des données. Il est donc important, lors du choix de la carte FPGA, de s’assurer que l’environnement de développement permet d’accéder aux blocs d’interface PCIe, de contrôle de mémoire DDR et de "Switch" prêtes à être mises en œuvre rapidement.
Enfin une dernière méthode de parallélisation sur FPGA consiste à utiliser l’outil générateur de blocs IPs, disponible avec l’outil de développement FPGA. Par exemple, le "Core Generator" de Xilinx Vivado permet de générer rapidement des fonctions de traitement de signal, des opérations arithmétiques et certains algorithmes d’encodage (Reed Solomon par exemple). Cette méthode requiert une bonne expertise de l’outil de développement FPGA. Là encore il reste à mettre en œuvre les autres blocs permettant d’accéder aux ressources physiques de la carte FPGA. Le protocole "Open Core Protocol" qui standardise l’interface de communication entre les différents blocs fonctionnels facilite l’intégration du design FPGA.
Le projet de recherche collective PSOPP a pour objectif l’établissement d’une méthodologie permettant d’adapter les logiciels des PME conçus pour une exécution sur processeur (CPU) mono-cœur vers une exécution sur processeurs graphiques (GPU), sur CPU multi-cœurs ou sur plateforme accélératrice FPGA de manière à tirer le meilleur profit de puissance de traitement qu’offrent ces architectures. Dans ce cadre, des études de cas industriels ont été menées afin de valider cette méthodologie.
L’algorithme à accélérer calcule la probabilité correspondance entre une amorce ADN (courte séquence de nucléotides utilisée pour le séquençage ADN) appelée "primer" et des séquences connues (jusqu’à plusieurs millions de nucléotides).
Le calcul est réalisé pour chaque position du primer dans la séquence ADN, sur chacun des deux brins et dans les deux sens de parcours. Pour chaque position, il faut calculer l’énergie de liaison entre chaque nucléotides du primer et de la séquence à analyser. Les résultats sont stockés dans une matrice, pour un sens de parcours du primer sur un brin ADN.
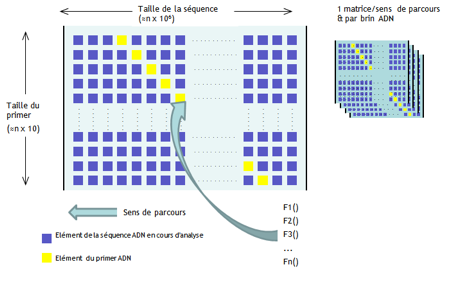
Pour une position du primer, le calcul de l’énergie de liaison nécessite plusieurs traitements parallèle et prend en compte le voisinage immédiat.
L’optimisation de l’algorithme consiste à déporter les traitements du CPU principal vers la plateforme accélératrice munie d’un FPGA Xilinx Virtex VI. Les calculs, principalement des opérations arithmétiques sur des entiers de 32 bits, sont mis en œuvre par des blocs fonctionnels générés à partir du code d’origine grâce à l’outil de compilation ROCCC. Le "pipeline" des calculs permet alors de traiter plusieurs éléments de la matrice simultanément. Le code VHDL ainsi obtenu est ensuite intégré au reste du design FPGA décrit précédemment.
La complexité des calculs et le volume important des données ont nécessité l’apport d’adaptations de l’algorithme. Tout d’abord un "fenêtrage" des données à transférer du CPU principal à la plateforme FPGA a du être réalisé compte tenu de la capacité du FPGA et de l’espace mémoire. De même l’amélioration des accès à la mémoire et des tests sur les résultats des calculs d’énergies ainsi que l’optimisation des données d’entrée ont été indispensables.
L’étude porte sur un simulateur de modem développé sous environnement Matlab et dont l’exécution non temps réel de la chaine complète de modulation / démodulation limite les performances.
L’ensemble basé sur une transmission multi porteuses met en œuvre des fonctions de traitements de signal (FFT, corrélation, filtrage…) et convient tout à fait à une implémentation sur accélérateur FPGA. Ainsi en réception, la récupération des trames de données par reconnaissance d’un motif nécessite un filtrage numérique dont les coefficients sont mis à jour par un calcul de la moyenne de n FFT, chacune calculée sur un bloc de m données de réception.
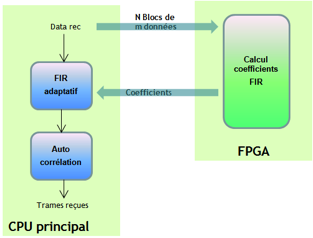
Le développement de cette fonction sur la plateforme accélératrice FPGA (Xilinx Virtex VI LX240T) est réalisé en utilisant le générateur d’IP de l’outil PlanAhead de Xilinx. Le bloc FFT ainsi obtenu est implanté dans le FPGA de la façon la plus optimale possible comparé aux autres outils de parallélisation sur FPGA. Les autres fonctions relatives au séquencement des opérations ont été codées en VHDl manuellement. Le traitement des données reçues en blocs sous forme d’entiers signés sur 16 bit, nécessite une précision des calculs intermédiaire en nombre flottant pour fournir les coefficients en entier signé 32 bit. Pour faciliter l’implémentation en FPGA l’algorithme a été adapté sans pour autant être modifié fonctionnellement. Ces adaptations concernent la taille du filtre, ainsi que des corrections de code bas niveau.
N’hésitez pas à contacter Gérard Florence, Ingénieur de Recherche Senior au CETIC, pour plus de détails à propos de cet article.