Dans cet article, nous présentons les fondements de l’analyse et du contrôle prescriptifs à l’aide de Machine Learning, en particulier dans le contexte de l’Industrie 4.0. Nous illustrons leur intérêt dans l’optimisation de l’utilisation de matières recyclées pour l’injection plastique, au travers de l’outil développé au sein du CETIC, TSAno (Time Series Anomalies), et de son application au projet Win 4Collective AI4Recycl, mené en partenariat avec le centre de recherche de l’industrie technologique Sirris.
Date: 22 août 2024
Expertises
Secteurs
Thèmes d’innovation
Auteurs
A l’ère de l’industrie 4.0, les besoins en analyse de données ne cessent de progresser. En particulier, l’analyse prescriptive se distingue par sa capacité à transformer des données brutes en recommandations pratiques, à l’aide de techniques avancées de Machine Learning. Contrairement aux analyses descriptives et prédictives, l’analyse prescriptive permet de fournir des recommandations d’actions pertinentes aux opérateurs et gestionnaires d’actifs, afin de réduire les coûts, minimiser le risque de rebuts ou de défaillances, ou encore améliorer la productivité des processus. Les avantages de l’analyse, maintenance et contrôle prescriptifs deviennent ainsi décisifs pour la compétitivité des entreprises.
Comme l’illustre la matrice d’impact ci-dessous, l’analyse prescriptive peut être vue comme le niveau ultime de l’analyse des données, apportant le plus de valeur ajoutée mais en contrepartie d’un effort de développement plus important. L’analyse prescriptive ajoute ainsi un niveau de complexité à la plus connue analyse prédictive, tout en en tirant pleinement partie.

Ces derniers temps, le département DSIDE du CETIC a développé un outil d’intelligence artificielle innovant adaptable à une grande diversité de tâches d’analyse dans un vaste spectre de problématiques industrielles, avec la flexibilité et l’interprétabilité au cœur des préoccupations. En effet, les processus industriels requièrent de plus en plus souvent l’analyse en continu de séries temporelles multivariées correspondant typiquement à l’évolution dans le temps de grandeurs issues de plusieurs capteurs.
Par ailleurs, il est crucial de pouvoir détecter au plus tôt toute anomalie survenant dans le processus et prendre les mesures adéquates pour la corriger. Dans certains cas, étant donné les corrélations entre les différentes séries temporelles monitorées, des anomalies multidimensionnelles peuvent apparaitre, et il n’est pas suffisant de surveiller uniquement l’évolution — et les éventuelles dérives — de chaque variable individuellement. La figure suivante illustre intuitivement cette limitation dans le cas de deux variables corrélées : un échantillon peut très bien se situer en deça des tolérances (typiquement, +/-3 sigma) pour chaque variable individuellement, mais se situer en dehors de l’ellipse "d’acceptation" pour la distribution bivariée sous-jacente étant donné les corrélations entre variables. La statistique permettant de rendre compte de l’éloignement d’une donnée à sa moyenne (vecteur) dans le cas multivarié, tout en tenant compte des corrélations, est le T-Squared de Hotelling (T^2). Dans le cas 2D, une valeur arbitraire du T^2 correspond au contour d’une ellipse sur le schéma ci-dessous et permet ainsi de définir un seuil d’acceptation/rejet pour chaque échantillon de donnée. Plus de détails sur le Hotelling T-Squared (mathématique, conditions d’application, etc) ainsi que son implémentation "façon Scikit-Learn" effectuée au CETIC, sont librement disponibles ici.

Dans la pratique, il est intéressant pour un opérateur de disposer à tout moment d’une information synthétique sur le process sous forme d’un score unique renseignant sur la "santé" du process : si ce score est supérieur à un seuil prédéfini, une dérive est constatée et nécessite potentiellement une action corrective.
C’est là que l’analyse prescriptive entre en action : une fois l’anomalie constatée, il est intéressant de retrouver ses causes, c’est-à-dire la combinaison de variables à l’origine de l’anomalie, puis d’identifier les leviers permettant de corriger la dérive.
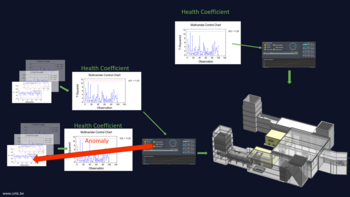
L’algorithme TSAno (Time Series Anomalies) du CETIC est capable de détecter les anomalies ou dérives sur les séries temporelles multivariées potentiellement non-stationnaires (c’est-à-dire, variant dans le temps) et est à même de fournir différents niveaux d’analyse (monitoring multivarié et analyse prescriptive). Son architecture globale est représentée ci-dessous.

Décrivons brièvement les différents "building blocks" de la figure, correspondant chacun à une fonctionnalité spécifique de TSAno.
Passons maintenant à un cas d’application concret de TSAno.
Dans le cadre du projet Win4Collective AI4Recycl, mené conjointement avec SIRRIS, nous avons appliqué TSAno à l’optimisation de l’utilisation de plastique recyclé dans un processus d’injection. Le procédé étudié est celui d’une machine d’injection plastique recevant des granulés de plastique en entrée et produisant diverses pièces moulées en sortie (voir image ci-dessous).

Un challenge majeur est de garantir la qualité de ces pièces quelle que soit la composition (fluctuante !) de la matière d’entrée. Une première hypothèse (forte) de travail est que la qualité du produit final sera garantie si la qualité du process l’est, ce qui amène à monitorer les variables de sortie du processus (au niveau du moule) afin de détecter puis essayer de corriger toute dérive à leur niveau. Le caractère prescriptif du contrôle de procédé apparait déjà : comment ajuster les paramètres de contrôle lorsqu’une dégradation des paramètres de sortie est observée ?
Dans ce cas-ci, des premières expériences ont permis d’identifier 3 paramètres de sortie les plus sujets à des variations, qui ont été retenus pour l’analyse. Il s’est avéré que ces variations étaient fortement liées à la variation de nature de la matière plastique en entrée, en particulier le Melt Flow Index (MFI) caractérisant la fluidité de la matière. Ainsi, des dérives des paramètres "moule" apparaissent lorsque la composition de la matière d’entrée fluctue, et en particulier, en présence de matière recyclée. Malheureusement, la mesure du MFI est approximative (basée sur des échantillons) et impossible à obtenir en continu dans la pratique, et les 3 paramètres mentionnées plus haut font donc office de softsensors du MFI. En déterminant les variables de contrôle qui influencent ces paramètres de sortie et de quelle manière, il serait possible de prescrire des recommandations d’actions sur ces variables de contrôle pour restaurer la qualité en sortie de process.
Sur base de la connaissance du procédé, 4 paramètres d’entrée ont été identifiés comme particulièrement susceptibles d’influencer la valeur des 3 paramètres de sortie analysés. Afin de modéliser la relation entre ces variables d’entrée et de sortie, des plans d’expérience (DoE) ont été réalisés, selon la méthode de Taguchi : ceci consiste à tester diverses combinaisons judicieusement choisies des paramètres d’entrée afin de balayer au maximum l’espace de variations de ces paramètres en un nombre raisonnable d’expérimentations (voir ici pour une explication détaillée). Ces plans d’expérience, réalisés sur des matières pures aux caractéristiques bien déterminées, ont fourni des données d’entrainement à partir desquelles le framework TSAno (voir section précédente) a pu être mis en œuvre : les 3 variables de sortie ont été modélisées à l’aide d’une régression linéaire robuste en fonction des 4 variables d’entrée. Le choix d’un modèle simple s’est justifié par l’observation des données, tout en évitant le surapprentissage.
Fort de ce modèle entrainé, TSAno est ensuite à même de détecter les anomalies en temps réel en phase de production, grâce au calcul du T-Squared et sa comparaison à un seuil prédéfini (en pratique, fine-tuné par essais/erreurs). La phase prescriptive consiste alors dans un premier temps à identifier les variables d’entrée les plus corrélées (sur base du DoE) avec les variables de sortie dont les résidus sont trop élevés. En effectuant une correction adéquate de ces variables de contrôle et par le jeu des corrélations, les variables de sortie incriminées évoluent à leur tour de manière à contrer la dérive. Plus précisément, cette correction s’effectue à l’aide d’une optimisation tenant compte d’éventuelles contraintes (bornes de variations maximales, valeur minimales/maximales, etc), basée sur le modèle de Machine Learning entrainé. L’opérateur dispose alors de recommandations de corrections de paramètres contrôlables afin de réduire la dérive du process.
L’efficacité de la prescription est visible sur la figure ci-dessous.

Les valeurs cibles des variables de sortie et les corrélations entre entrées et sorties sont présentes dans la partie gauche. Pour faciliter la compréhension, cet exemple ne comporte une dérive que sur une variable de sortie, la pression p4072. Sur base de l’évolution du T^2, diverses corrections sont suggérées par l’algorithme en cas de dérive, notamment suite à l’introduction de matière recyclée dans le process. La latence dans l’établissement de certains paramètres (notamment les températures) requiert une certaine tempérance de l’algorithme quant à l’envoi de recommandations d’actions.
Notons, bien que cela ne soit pas l’objet de cet article, que les échanges de données et de recommandations entre le script d’IA et l’applicatif de SIRRIS ont été rendus possibles par le middleware DMWay, développé au CETIC, à propos duquel vous trouverez plus d’infos ici.
Lorsqu’on utilise un modèle de machine learning, il faut veiller à ce que l’application du modèle (inférence) s’effectue sur des données pas trop éloignées de celles utilisées pour l’entrainement. Si le process évolue dans le temps (vieillissement de l’équipement, changement de conditions opératoires, etc), il peut être nécessaire d’également mettre à jour le modèle à l’aide de données plus récentes. C’est ce que l’on appelle la continuation d’entrainement. Un modèle prescriptif dynamique doit alors être conçu afin de rester valide lorsque de nouvelles exigences ou contraintes surviennent.
Pour en savoir plus à ce propos, consultez notre autre article de blog sur la continuation d’entrainement, à paraitre prochainement !
Dans cet article, nous avons présenté les fondements de l’analyse prescriptive ainsi que le framework TSAno développé au sein du département DSIDE du CETIC. Nous avons insisté sur les différents niveaux d’analyse offerts par TSAno dans l’analyse de séries temporelles multivariées, avec l’explicabilité au cœur des préoccupations. Nous avons montré un cas d’usage fructueux de l’analyse prescriptive, et de TSAno, dans le domaine de la plasturgie. La nécessité de concilier analyse des données avec expertise métier a une fois de plus été démontrée.

L’analyse prescriptive offre de nombreuses perspectives pour les entreprises manufacturières de divers domaines, notamment dès que des données de type IoT ou en flux sont disponibles. L’analyse prescriptive est un outil puissant pour améliorer le contrôle des processus grâce aux données, tout en garantissant l’interprétabilité des recommandations fournies.
Si vous pensez que le CETIC pourrait aider votre entreprise à mettre en œuvre un projet sur l’analyse prescriptive, n’hésitez pas à nous contacter !