
Les entreprises sont de plus en plus confrontées aux défis posés par le traitement de données massives. Bien qu’un large éventail de solutions techniques soit disponible pour traiter ces "Big Data", beaucoup peinent à les déployer parce qu’elles peinent à organiser l’exploitation de leur données. Dans le cadre de la Plateforme d’Innovation Technologique Big Data, le CETIC propose une guidance en la matière en s’ancrant à la fois sur des référentiels reconnus et sur une série de pilotes menés dans des secteurs clefs.
Notre monde est actuellement confronté à une explosion de l’information. De nombreuses statistiques attestent de la montée en puissance du phénomène Big Data car 90% des données dans le monde ont été produites durant ces deux dernières années et le volume des données créé par les entreprises double toutes les 1,2 années [1].
Bien que les entreprises perçoivent bien le grand potentiel que les technologies Big Data peuvent leur apporter pour améliorer leur performance, le constat est que beaucoup peine à retirer de la valeur et un avantage compétitif de leurs données. Un rapport de 2013 a révélé que 55% des projets Big Data se sont terminés prématurément et que beaucoup n’ont que partiellement atteint leurs objectifs [2]. Une étude en ligne conduite par Gartner en juillet 2016, montre aussi que de nombreuses entreprises restent bloquées au stade du projet pilote : seulement 15 % des projets Big Data ont été effectivement déployés en production [3].
En examinant la cause de tels échecs, il apparaît que le facteur principal n’est en réalité pas lié à la dimension technique, mais plutôt aux processus et aux aspects humains qui s’avèrent être aussi importants. Le travail du CETIC s’est concentré sur cette dimension et vise à apporter des recommandations concrètes aux entreprises engagées dans un processus d’adoption de solution Big Data pour notamment répondre à des questions telles que :
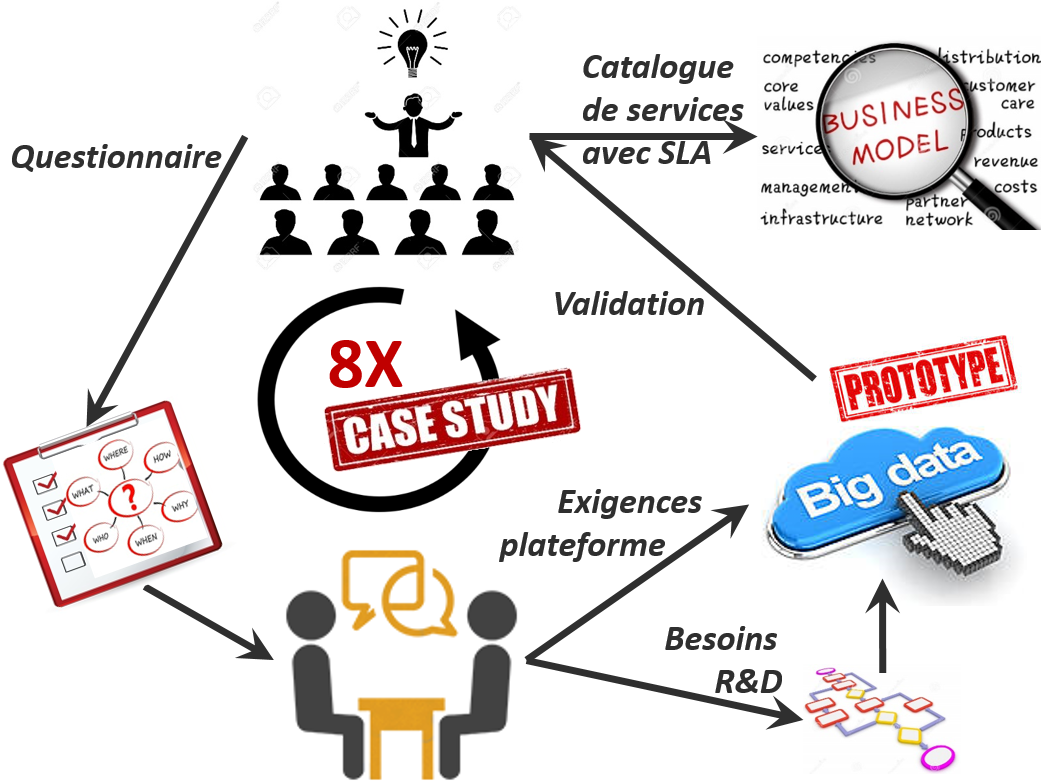
Notre approche s’appuie d’une part sur l’examen et la combinaison de méthodes existantes de domaines apparentés ou complémentaires tels que la fouille de données ("Data Mining" - DM), l’nformatique décisionnelle ("Business Intelligence" - BI) et les méthodes Agile. D’autre part nous avons collecté des retours d’expérience sur base d’une série de pilotes déployés dans divers secteurs, selon la méthodologie illustrée à la figure suivante. Le reste de cet article détaille ces 2 dimensions.
Fouille de données et intelligence décisionnelle
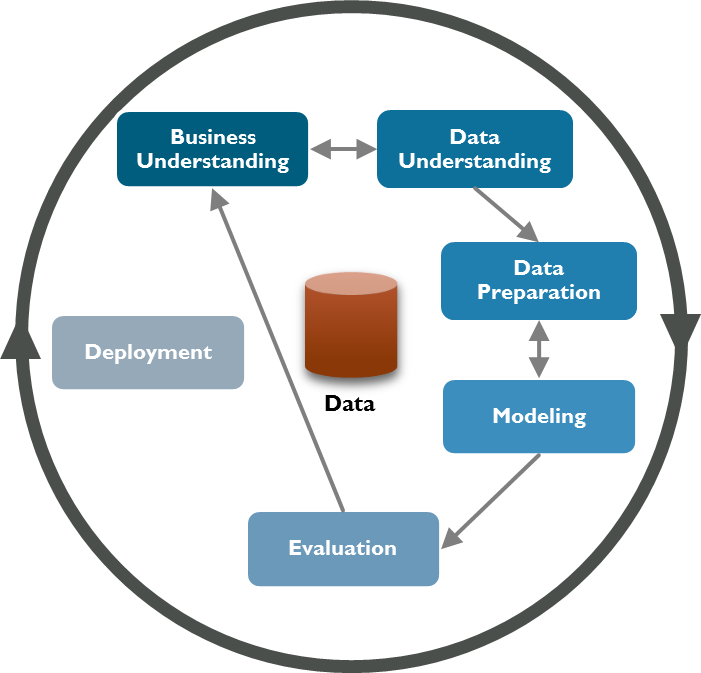
Un des domaines les plus ancien apparenté au Big Data est la fouille de données ("Data Mining") a été développée dans le courant des années ’90 avec pour objectif d’extraire des données à partir d’informations structurées (bases de données) pour découvrir des facteurs clés de l’entreprise à une échelle relativement petite. Le Big Data, quant à lui, opère sur des données structurées ou non. Outre les notions de volume et de valeur déjà mentionnés, il assure aussi des impératifs de vitesse de traitement. Cependant, en termes de processus les deux domaines ont des besoins similaires : il est nécessaire de mettre en place une coopération étroite entre les experts techniques (données) et les experts métiers. De nombreuses méthodologies et modèles de processus ont été développés pour la fouille de données et la découverte de connaissances. Elles ont abouti à un standard CRISP-DM (Cross Industry Standard Process for Data Mining [4]. Cette méthode illustrée ci-dessous est composée de six phases, chacune étant décomposée en sous-étapes. Le processus n’est pas linéaire, mais plutôt organisé comme un cycle global avec généralement des revues entre les phases. CRISP-DM a été largement utilisé depuis 20 ans, non seulement pour la fouille de données, mais reste largement utilisée pour l’analyse prédictive et des projets Big Data.
L’informatique décisionnelle s’est également développée dans les années ’90 et a pour but essentiellement de produire des indicateurs clé de performance (en anglais KPI : Key Performance Indicator) sous forme de tableaux de bord. Les techniques s’appuient sur des données structurées et ne nécessitent que peu d’intelligence dans les traitements. Le Big Data permet d’élargir le champ de la BI aux données moins structurées. Inversement, la BI apparaît comme un prérequis permettant de mesurer précisément ce qu’on désire améliorer tandis que les techniques Big Data apportent des possibilités d’analyse prédictive.
Vers plus d’agilité
Bien que comportant des possibilités de retours en arrière, elle n’organise pas ce processus en mettant le client et la production de valeur au centre du processus telle que le font les méthodes Agiles. Initialement développées pour le développement de logiciels, ces principes peuvent également répondre plus largement et en particulier à l’analyse des données afin de fournir une meilleure guidance. Diverses variantes de ces méthodes existent.
Gestion de la montée en maturité
Les méthodes agiles ne sont à elles-seules pas garantes d’un succès d’un projet : il importe de s’assurer que le projet évolue correctement vers le résultat visé. A cette fin plusieurs outils sont disponibles :
| pour les données | la qualité, la sécurité, le niveau de structure des données |
| pour la gouvernance | une direction, une organisation bien définie, une culture axée sur les données |
| pour les objectifs | la valeur de l’entreprise identifiée (KPI), la rentabilité, une taille de projet réaliste |
| pour les processus | l’agilité, la conduite de changement, la maturité, la volumétrie des données |
| pour l’équipe | des compétences en ingénierie des données, la multidisciplinarité |
| pour les outils | des infrastructures informatiques, le stockage, la capacité de visualisation des données, le suivi des performances |
Nous décrivons ici la méthodologie qui a émergé sur base des méthodologies décrites précédemment ainsi que de l’expérience de mise en œuvre sur 4 pilotes industriels wallons. Ceux-ci sont ciblés les domaine suivants : maintenance d’infrastructures IT, santé, spatial et pharmaceutique. Nous donnons ici qu’un aperçu succinct.
Schéma général appliqué au sein de chaque pilote
La méthodologie qui a émergé sur base des méthodologies existantes et sur base des itérations sur nos 4 pilotes se compose de trois phases suivantes :
Retour d’expérience et recommandations
Voici quelques éléments clefs relatifs aux retours d’expérience et recommandations relativement aux 1 et 2 :
Nos travaux ne sont pas achevés et de nouveaux pilotes sont en cours d’identification afin de généraliser nos recommandations à d’autres domaines d’activité. N’hésitez pas à nous contacter si vous désirer disposer de recommandations plus détaillées voire de nous consulter par rapport à votre projet de déploiement Big Data.
[1] Rot, E. (2015). How Much Data Will You Have in 3 Years ?
[2] Kelly J., Kaskade J. (2013). CIOs & Big Data : What Your IT Team Wants You to Know
[3] Gartner. (2016). Investment in big data is up but fewer organizations plan to invest
[4] Shearer C. (2000). The CRISP-DM Model : The New Blueprint for Data Mining. Journal of Data Warehousing, vol. 5, no 4.
[5] Crowston, K. and Qin, J. (2011), A capability maturity model for scientific data management : Evidence from the literature. Proc. Am. Soc. Info. Sci. Tech., 48 : 1–9.
[6] Nott C. (2014). Big Data & Analytics Maturity Model