
Mettre à jour votre site web : un casse-tête ? Il existe des technologies de migration de sites Internet statiques vers des gestionnaires de contenu. Cet article décrit une méthode et son logiciel prototype.
Design maladroit, technologies inadaptées au volume d’information à traiter, manque de documentation ou code illisible : telles sont les raisons qui peuvent considérablement entraver la mise à jour d’un site Internet. Conçu pour résister autant que possible à l’érosion du temps, un site se doit alors de respecter certains critères de maintenabilité.
Alors que le volume et la rapidité de changement des informations ne cessent d’augmenter, les sites statiques, construits il y a déjà plusieurs années, doivent pouvoir à tout moment maintenir une information complète, correcte, pertinente et non-contradictoire ainsi qu’un design global homogène. Les responsables du système doivent alors opter pour une solution plus "moderne" basée sur des systèmes d’information performants, bien structurés et sur des programmes qui construisent les pages du site de manière dynamique, à la demande de l’utilisateur. Dans ce contexte, les outils de gestion de contenu comme Plone ou SPIP offrent des solutions efficaces pour la gestion en temps réel du contenu d’un site. La méthode et les outils de rétro-ingénierie de sites web prototypés au CETIC démontrent comment il est possible de migrer vers un tel système. En effet, lorsque le volume d’informations présentes dans l’ancien système est relativement important, la récupération des données noyées au sein des pages statiques s’avère une étape primordiale dans le processus de migration.
La rétro-ingénierie de sites Internet consiste à extraire de pages HTML statiques les données et leur structure. Nous entendons par "donnée" tout élément d’information variable d’une page à l’autre et, par conséquent, susceptible d’être stocké dans une base de données ou dans un outil de gestion de contenu. La structure des données produite, quant à elle, est décrite par un schéma conceptuel, c’est-à-dire un schéma de type entités-relations ou UML (diagramme de classe), indépendant de toute technologie et répondant à un certain nombre de critères de qualité tels la lisibilité ou l’expressivité.
Le processus de rétro-ingénierie n’est qu’un travail préparatoire à une phase de création d’un nouveau système de bases de données et de migration des données de l’ancien système vers le nouveau. Produites dans un formalisme semi-structuré et interprété, les données résultantes du processus de rétro-ingénierie sont une base idéale pour la migration vers un nouveau système. Quant au schéma conceptuel, il sert de point de départ à un processus plus classique d’ingénierie de bases de données.
Le schéma ci-dessous détaille les cinq processus et les produits de notre méthode.
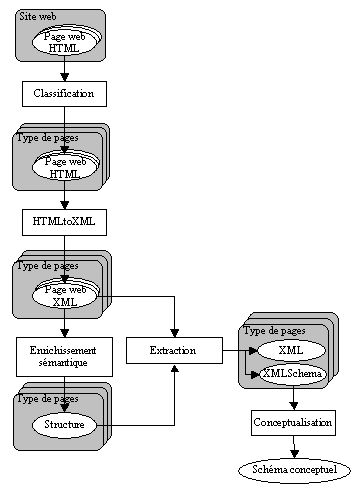
La classification des pages consiste à répertorier celles-ci en catégories (appelées "types de pages") selon le concept qu’elles représentent. Par exemple, chaque page affichant des informations sur un article vendu par une société appartient à un type de pages que l’on peut nommer "article". Une fois catégorisées, les pages sont transformées automatiquement en documents XML afin de pouvoir être traitées par des outils d’analyse tels des parsers.
Un enrichissement sémantique des pages est ensuite nécessaire. En effet, HTML est un langage de présentation utilisé pour formater les documents sur Internet. Par conséquent, un fichier HTML ne contient que (trop) peu d’information sémantique exploitable automatiquement. Difficile, en effet, pour une machine de découvrir que l’information "C00251" présente sur un site est, en fait, un numéro de commande ou que "Dupont" est le nom d’un client. Lors de cette étape importante, l’utilisateur précise donc la sémantique des informations qui sont affichées sur le site et qu’il souhaite extraire. Pour réaliser cette tâche, un "éditeur sémantique" a été développé au CETIC sur base du code open-source du navigateur Firefox. Ce module permet, par simple sélection de zones dans un document HTML, de déclarer des concepts et de leur associer une valeur. Pour chaque type de page, une première page est analysée à l’aide de l’outil et la structure de ce document est stockée dans un fichier descripteur.
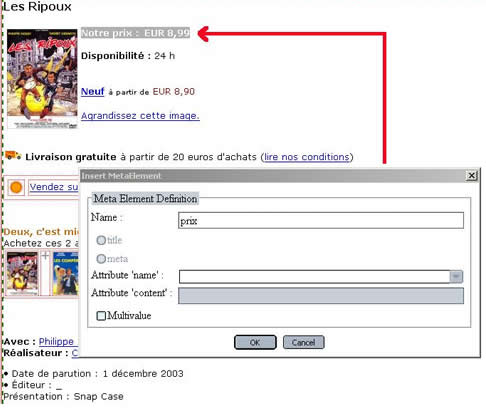
Un processus itératif sur toutes les pages d’un même type nous permet alors de déduire une structure commune à toutes ces pages. Celle-ci nous permet de localiser les données pertinentes au sein des pages et d’en connaître leur signification.
L’extraction des données et de leurs schémas consiste ensuite, à partir d’une structure décrivant un type de pages et les pages de ce type, à créer un premier fichier XML contenant les données des pages. Il peut être validé par rapport au second document produit (le XML Schema), qui décrit la manière dont les données doivent être structurées. Celui-ci est également extrait sur base des informations produites par l’utilisateur lors de la phase précédente. Des modules logiciels écrits en Java réalisent ces travaux de validation d’une page HTML par rapport à sa structure et d’extraction de données et schémas.
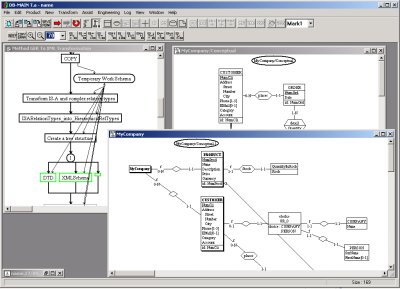
L’étape finale est l’intégration et la conceptualisation des schémas. A ce moment de la méthode, il existe un document XML Schema par type de pages découvert lors de la première étape. La production d’un schéma conceptuel intégré représentant la structure des données de l’entièreté du site est nécessaire. L’outil DB-Main->http://www.db-main.be] est utilisé pour intégrer et transformer les schémas de données. Il a été développé par le Laboratoire d’Ingénierie des Bases de Données de l’Université de Namur (LIBD), qui travaille en étroite collaboration avec le CETIC.
Que ce soit pour simplifier la mise à jour des pages, homogénéiser le design général du site ou proposer de nouveaux services en ligne, la migration d’un site statique vers une technologie dynamique doit, dans de nombreux cas, s’accompagner d’une phase préalable de rétro-ingénierie de l’ancien système. Celui-ci peut être vu comme un système d’information semi-structuré dans lequel les données pertinentes sont noyées dans des informations de présentation. Le CETIC propose une aide à propos des outils de support à la récupération des données d’un site Internet et à l’extraction d’un schéma de données, utile pour la documentation et la reconstruction d’un nouveau système de bases de données. Extraire de milliers de pages -pas toujours correctement rédigées- la quintessence de l’information est une tâche complexe requérant de multiples interventions de l’utilisateur (notamment pour l’ajout de sémantique au sein des pages), mais comme le prouvent nos recherches, ce travail peut être semi-automatisé par des outils d’analyse, de validation et d’extraction.