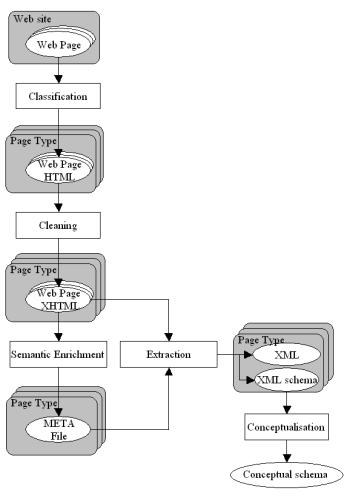
This article describes a method for web sites reverse engineering. It is composed of five processes: Web pages classification, HTML cleaning, Semantic enrichment, Data/schema extraction and Schemas integration.
Web pages within a site can be gathered into semantic groups according to their informational content. A page type is a set of pages relative to a same concept. For example, all pages describing the departments of a company belong to the page type "Department".
All HTML pages that should be analysed are transformed into well-formed XML documents in order to allow easy parsing and extraction.
Before data and schema extraction, we need to know, for each page type, what are the concepts displayed and where they are located in the HTML tree. For example, a page type "Department" will be composed of the concepts "Name", "Address" and "Activities". All semantic information provided by the user during that step will be stored into an XML document called the META file.
When the META file have been completed (i.e. it contains sufficient information to describe all the pages of the same type), it can be used to extract data from HTML pages and to store them in an XML document. This data-oriented document has to comply with an XML Schema that is also automatically extracted from the META file.
If a site comprises several page types, their XML Schemas must be integrated into a integrated logical schema that can then be conceptualized to represent the application domain covered of the whole web site.